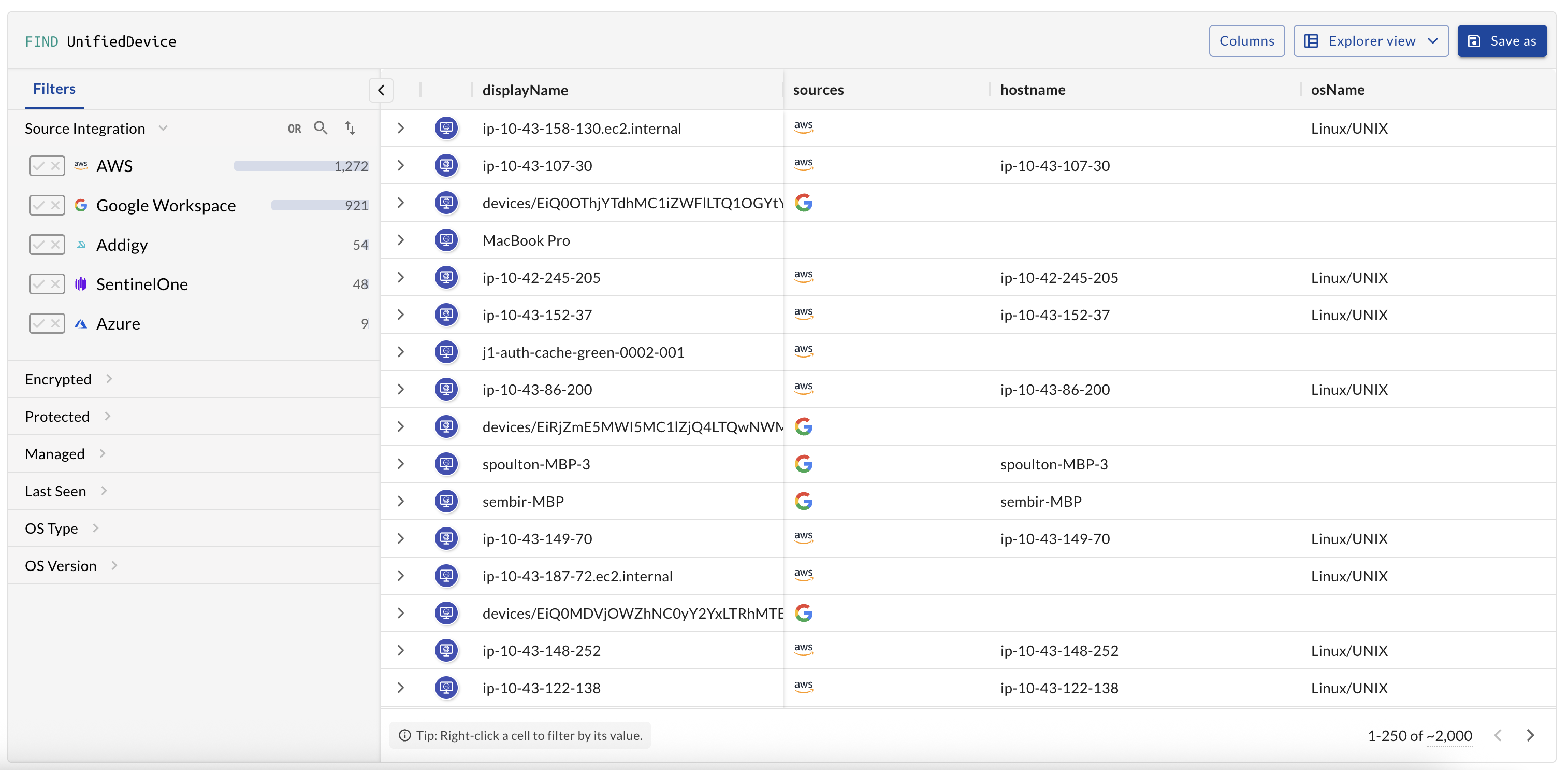
In my last two posts, I shared how I’ve been working on a flexible data explorer / query builder system. My main goal when approaching this feature was to build a scalable, modular UI system where custom bespoke view components would no longer need to be developed. By leveraging a stable filterManager and a static config, we get a stable, tested, scalable working UI. Essentially a big lever to pull to spin up new UI quickly.
Benefits of This Approach
- Composable UI modules that render based on user intent
- Live filter state with insights where to drill-down from live data populated in each filter section
- Custom views per entity, not a custom bespoke UI that becomes unmaintainable
- User-saved views, since we have a defined data structure describing the UI, users can create their own UI custom to their graph
- AI-generated views: Using our AI system, we inject context about the shape of a user’s graph and can dynamically create custom views with relevant filters based on that user’s specific graph.
This makes the UI layer configurable, stable, shareable, and generative.
Next Steps
To dynamically load in a config for the Data Explorer, we first begin by parsing the SQL query that the user input and see if it is eligible for this enhanced view.
We begin by detecting which entity the user is targeting after they put in their raw SQL query:
const extractEntity = (sql: string): string | null => {
const match = sql.match(/FROM\s+(\w+)/i);
return match?.[1] ?? null;
};
Then extract filters from the WHERE clause:
const extractFilters = (sql: string): Filter[] => {
const whereClause = sql.split(/WHERE/i)[1];
if (!whereClause) return [];
return whereClause
.replace(/;$/, "")
.split(/AND/i)
.map((clause) => clause.trim())
.map((clause) => {
const match = clause.match(/(\w+)\s*(=|!=|<|>|<=|>=)\s*['"]?(.+?)['"]?$/); // probably better to pull from a defined set
if (!match) return null;
const [, field, operator, value] = match;
return { field, operator, value: value.trim() };
})
.filter((f): f is Filter => !!f);
};
Then, before showing the UI, we populate the parsed filters into the filterManager.
filters.forEach((f) => filterManager.add(f));
After this, we look for which config to load which looks like:
const userConfig = {
rootNodeTarget: "User",
defaultFields: ["id", "email", "created_at"],
icon: "user",
filters: [
{
id: "status",
label: "Status",
type: "checkbox",
field: "status",
operator: "IN",
sql: `
SELECT status AS value, COUNT(*) AS count
FROM users
GROUP BY status
`,
},
{
id: "email_domain",
label: "Email Domain",
type: "checkbox",
field: "email",
operator: "LIKE",
sql: `
SELECT SPLIT_PART(email, '@', 2) AS value, COUNT(*) AS count
FROM users
GROUP BY value
ORDER BY count DESC
`,
},
],
};
We then load the right config based on the detected entity:
const config = entity ? configs[entity] : null;
if (config) {
// boot up UI, preload results, mount graph
}
That’s it. The system renders the view if the query meets Data Explorer criteria, and populates the UI, just from the input string and config.
Applied Principles
This system was built around a few key ideas:
- Encapsulation – All filter logic is owned by the hook, not scattered in views
- Inversion of Control – The input drives the UI, not the other way around
- Determinism – Same input string always yields the same visual + backend state
- Composable architecture – Configs act as the schema, the hook as the runtime
- Scalability through abstraction – Adding a new entity means adding a config, not writing new views
This turns our UI into a declaration. I don’t have to create new custom views as we expand this feature, we just describe what want in SQL, and the system builds the rest.
And because it’s just config + state, it opens doors:
- Saved data explorer views
- Ability to create new Data Explorer views quickly
- Ability for users to create their own relevant Data Explorer Views
- Ability for AI to generate relevant Data Explorer views based on graph shape
- Support new entities supported instantly via a config